Ground Truth vs Model
In the OCR setting, our goal is to train our models such that the predicted text is as close to the ground truth. Sometimes, it might be useful to visualize the exact characters that have been wrongly predicted by our models. To do so the OCR tool has provided a diff visualizer.
The gif below should help understand how to use the feature.
Model Truth vs Model
When you have outputs from multiple models, you may want to see the difference of two strings between those two models. The OCR layout provides a mechanism to do so.
Notation
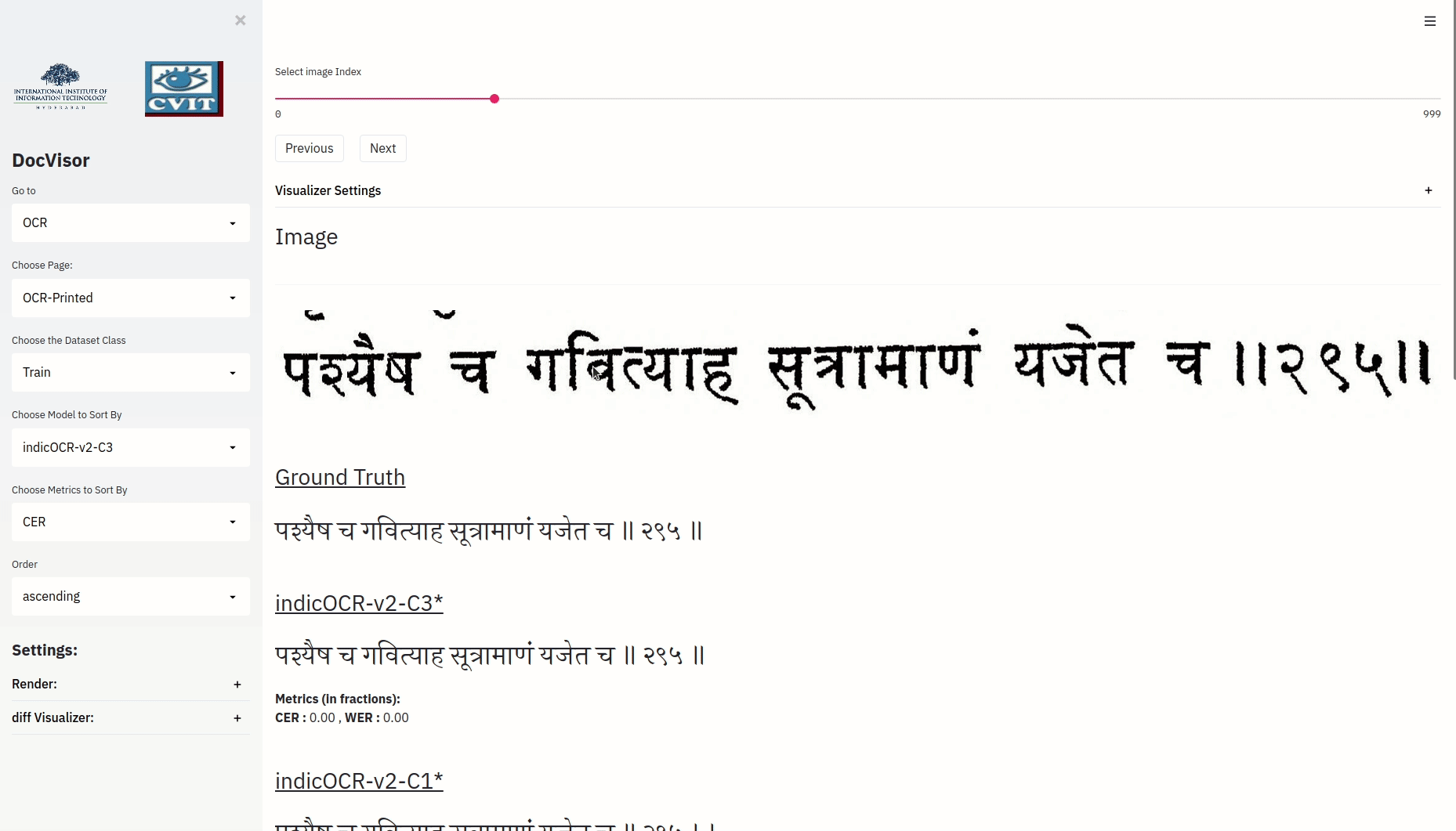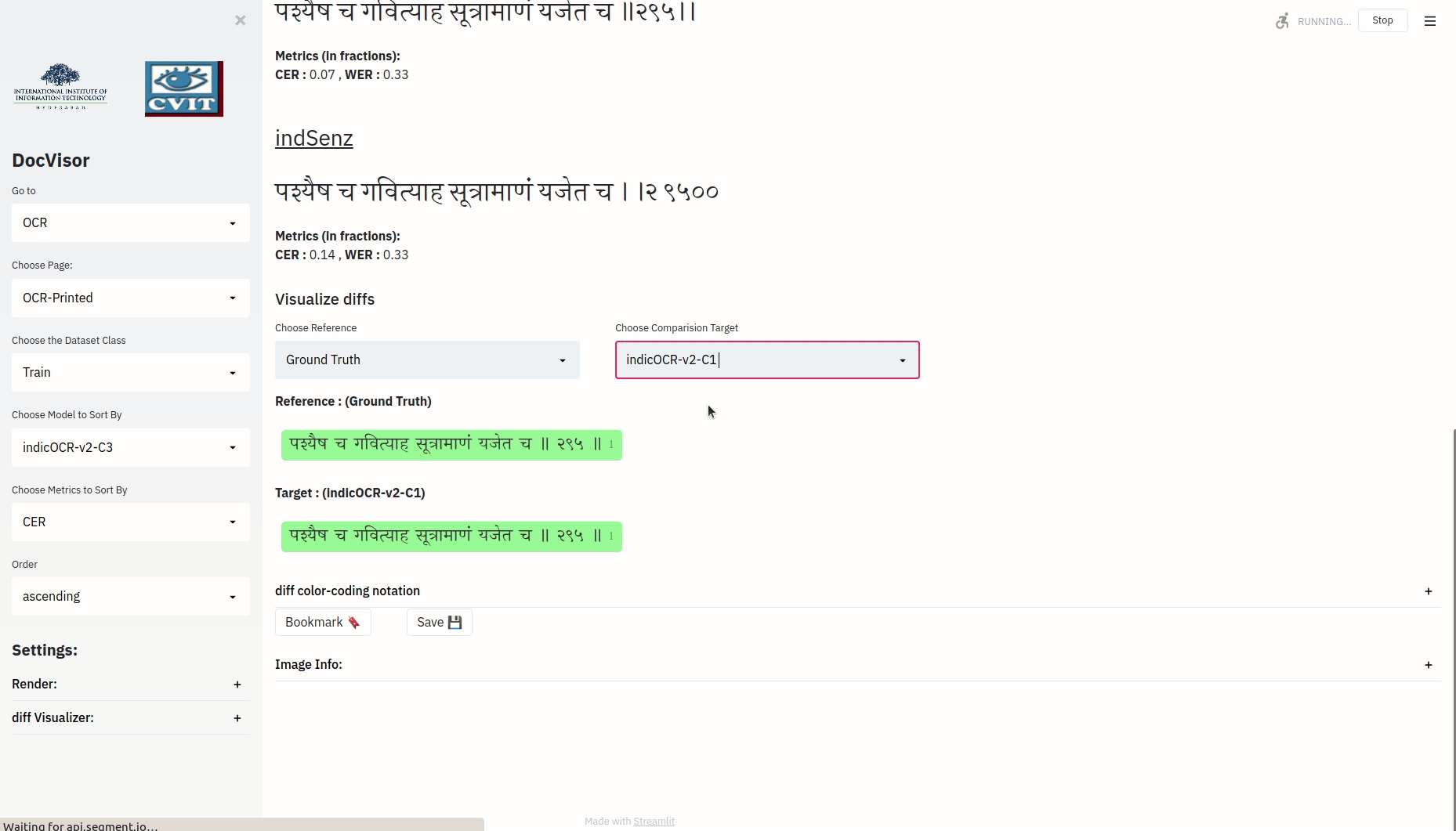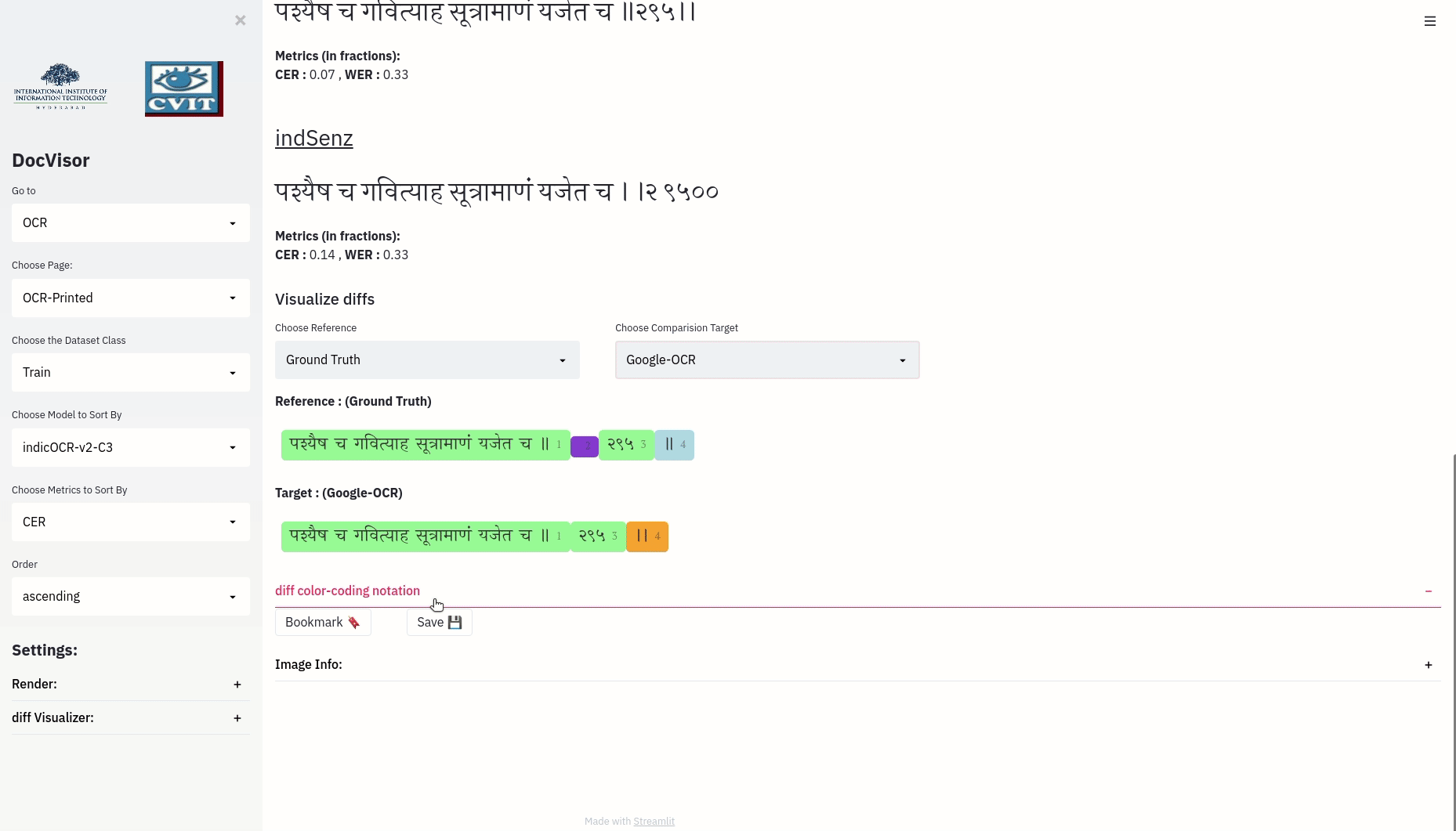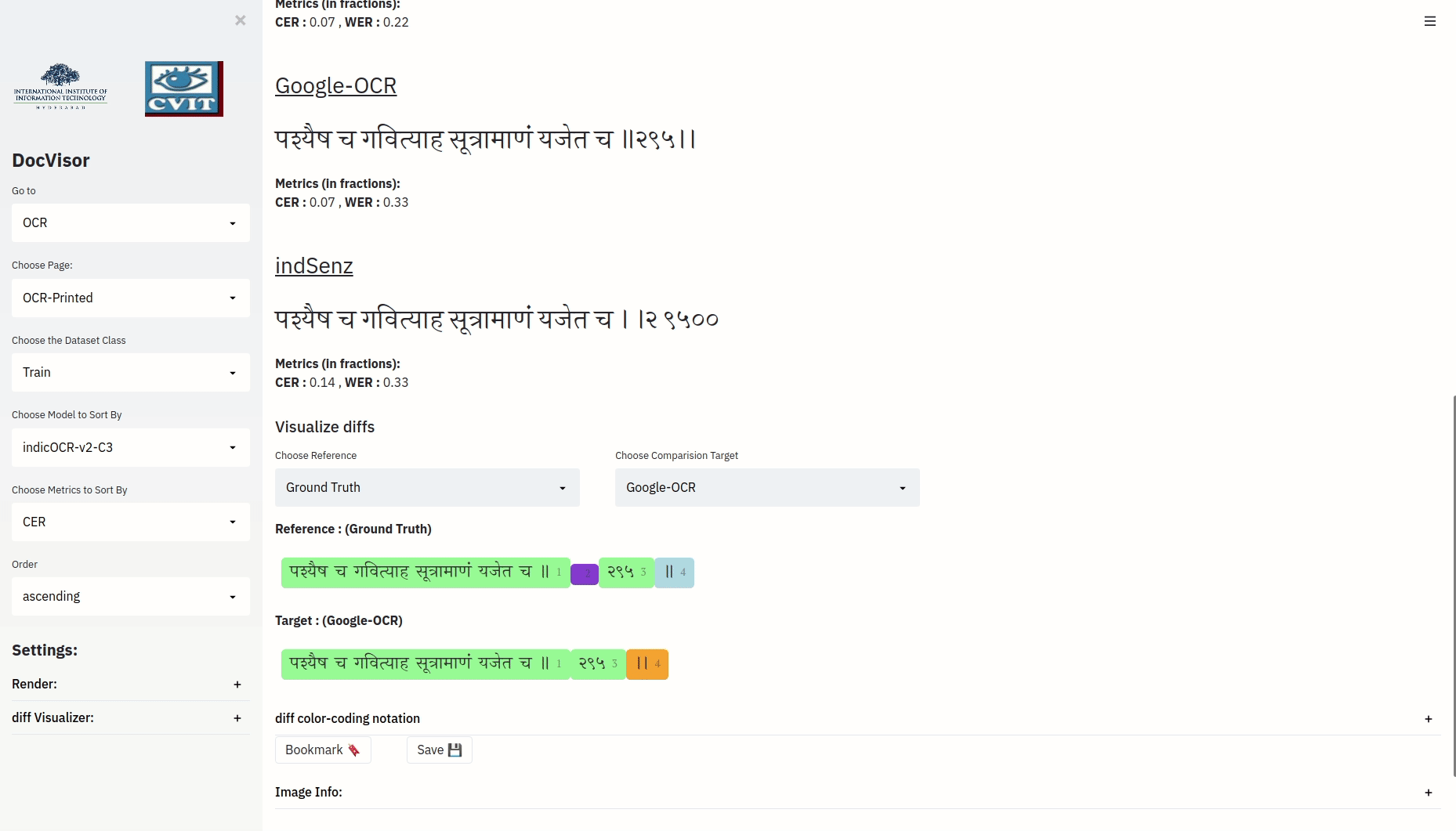
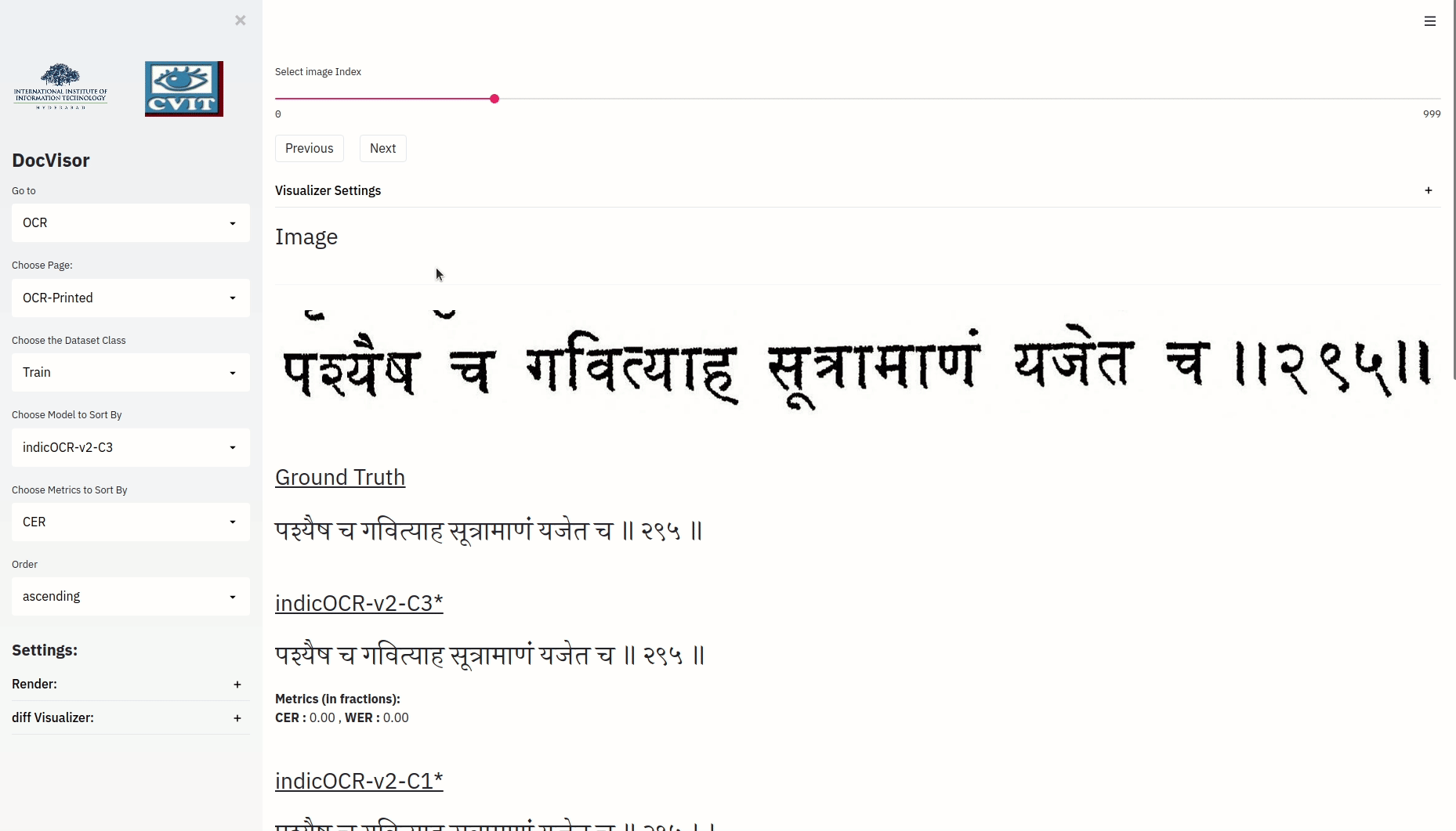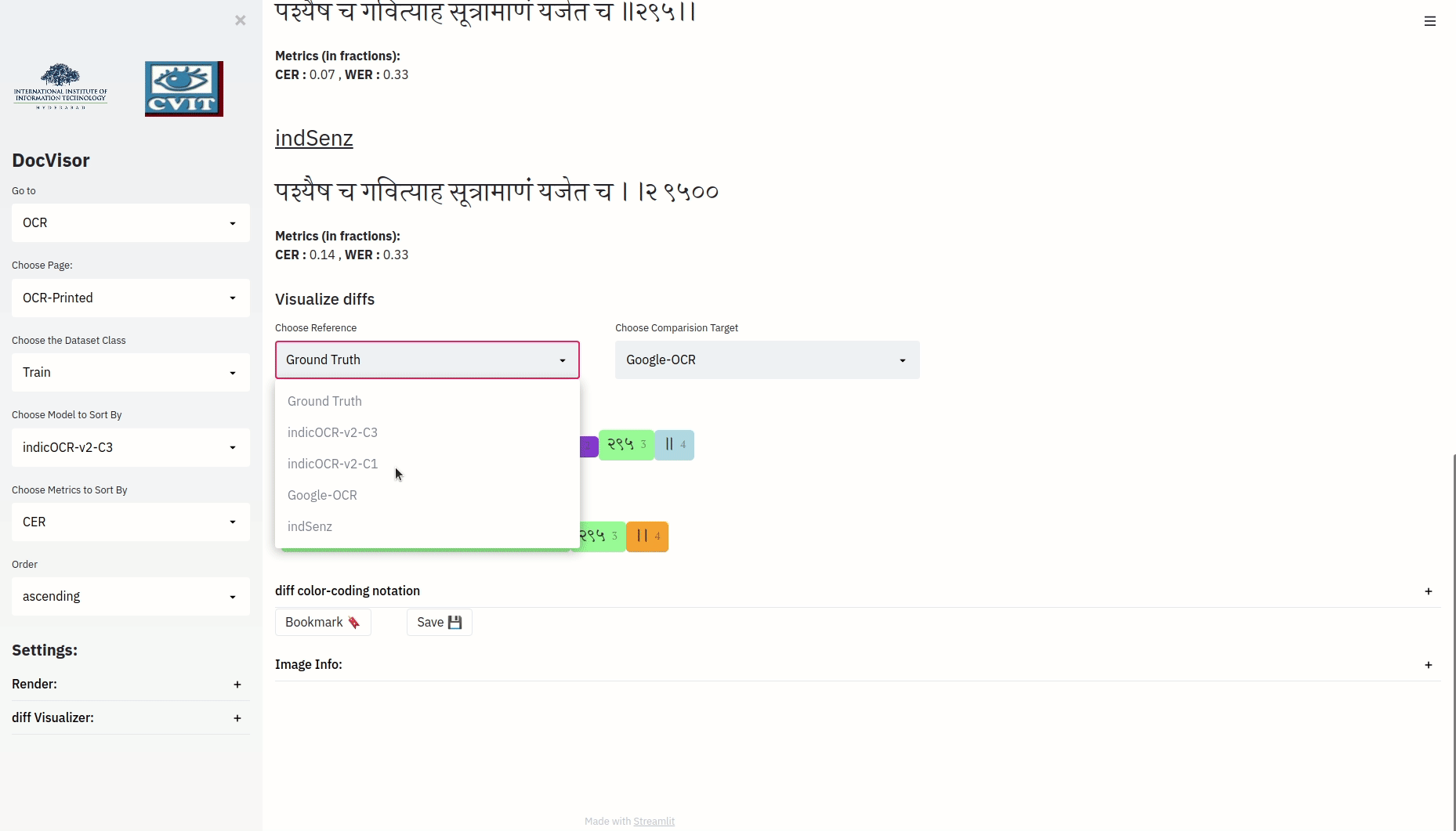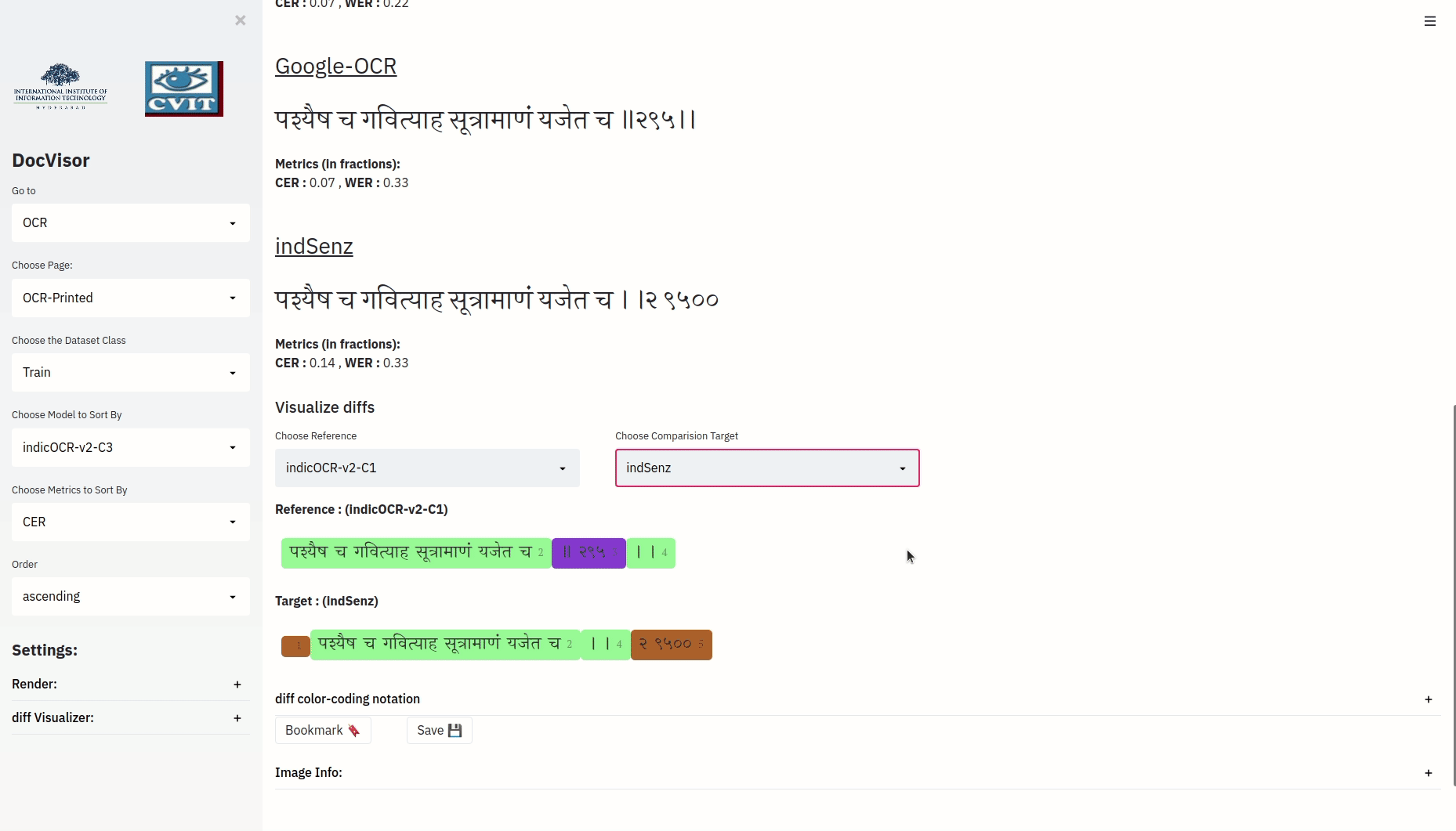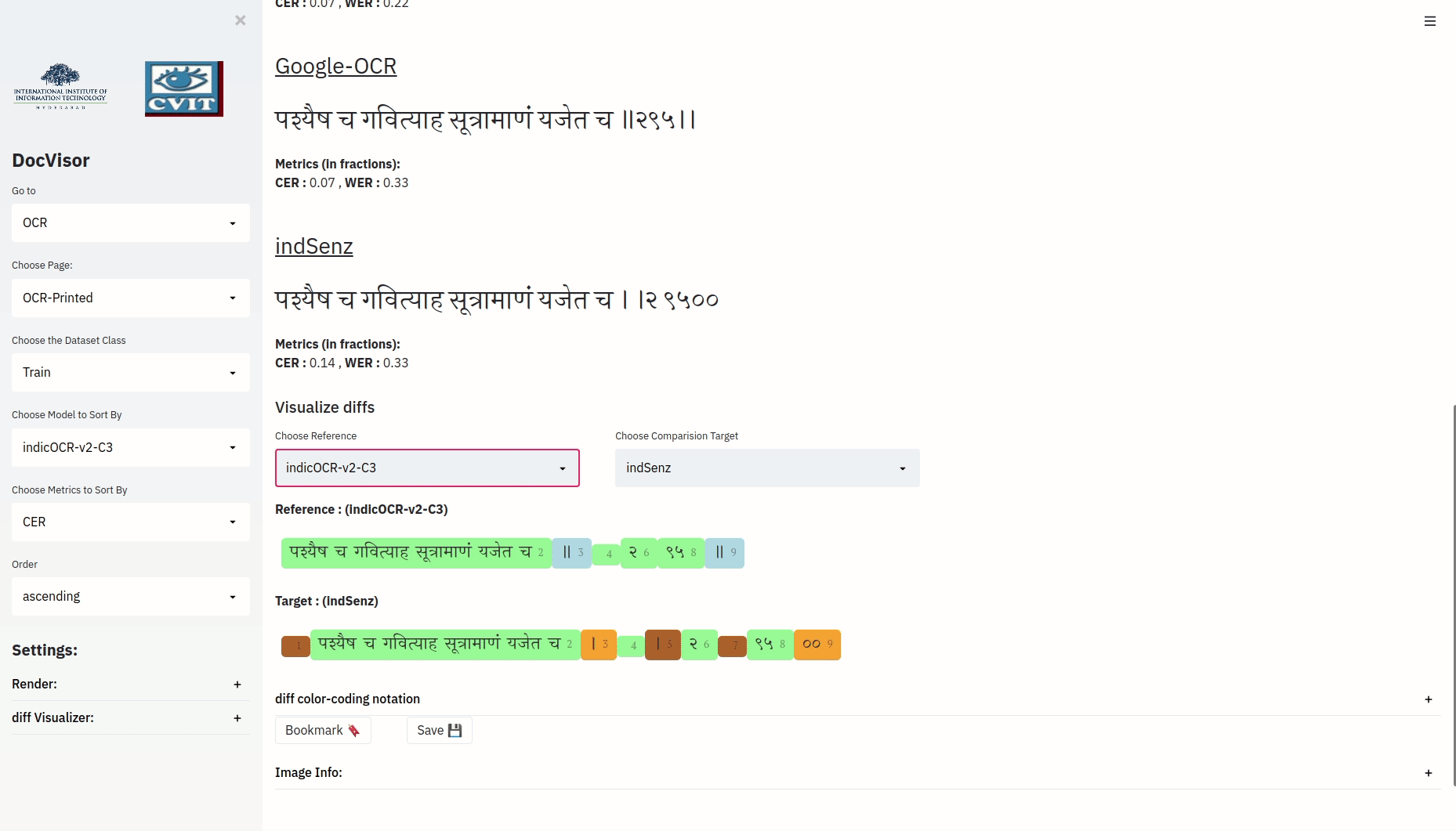
The above visualization, depicts the minimal operations required to convert the target string to the reference string. Notice that every distinct color bounded-text is also annotated with numbers. Also notice that for a color bounded component in the reference string with annotation i, there could be a corresponding color bounded text annotated with the same number i in the target string. (the color of these two color-bounded texts need not be the same).
| Color of reference Component i | Color of Target Component i | What does it Mean? |
|---|---|---|
| ‘<some-reference-text>(i)’ | ‘<some-target-text>(i)’ | Component i of reference and component i of the target are Equal |
| ‘<some-reference-text>(i)’ | non-existent | Insert Component i of reference after component i-1 of target |
| non-existent | ‘<some-target-text>(i)’ | Delete Component i of target |
| ‘<some-reference-text>(i)’ | ‘<some-target-text>(i)’ | Replace component i of target with component i of reference |