To be presented at ICDAR 2026



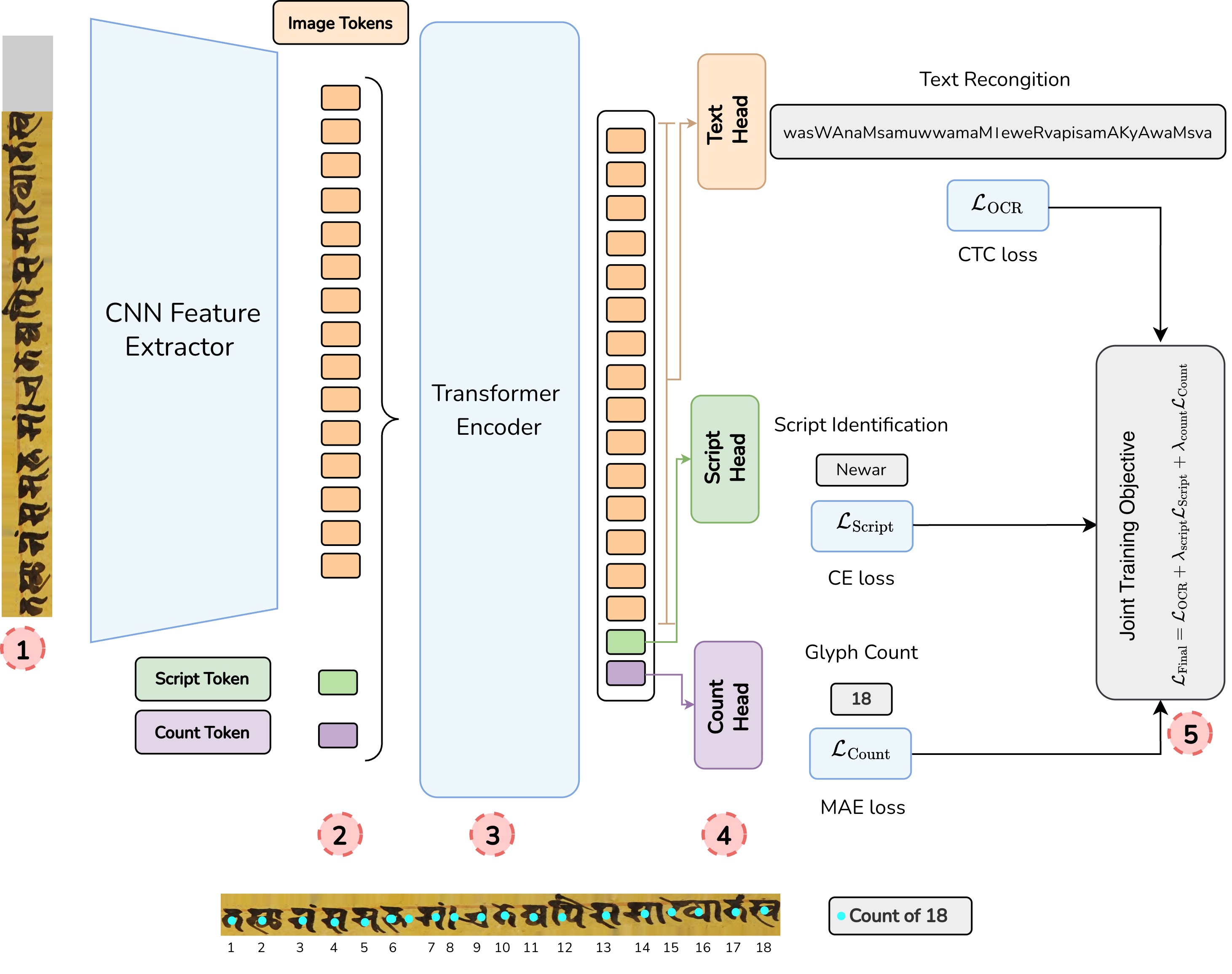
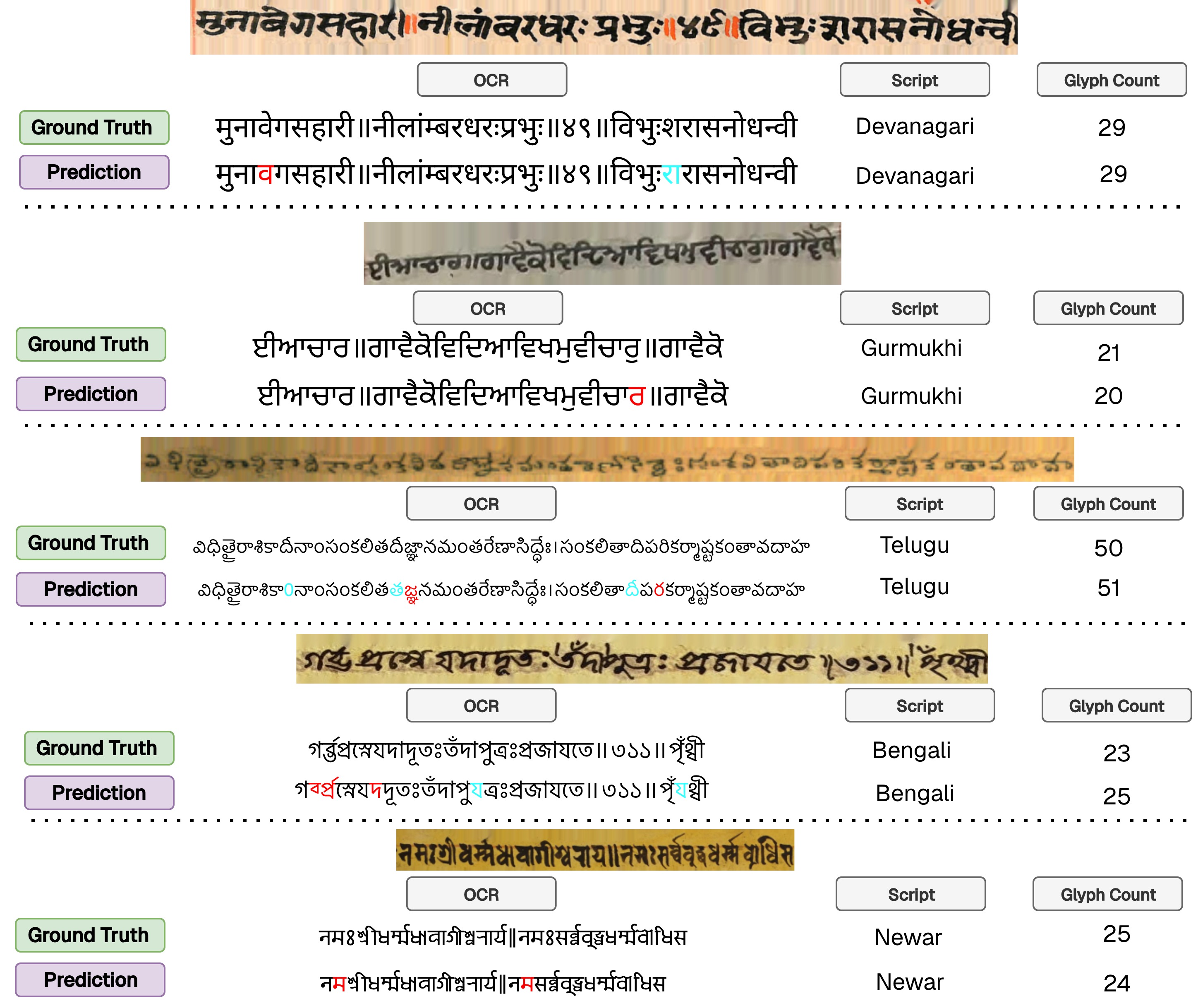
UniLipi: A Unified Multi-Script OCR for Historical Indic Manuscripts
A single OCR foundation model trained jointly across 13 Indic scripts.
International Institute of Information Technology, Hyderabad
tathagata.ghosh@research.iiit.ac.in · sai.gunda@research.iiit.ac.in · ssandral@gitam.in · ravi.kiran@iiit.ac.in
13Indic scripts
32.5MSynthetic lines
6.9%Overall CER
85MParameters