
HInDoLA system

Layout Parsing Deep Network

Layout parsing outputs

Examples of manuscripts
Printed Sanskrit OCR
HInDoLA system
Layout Parsing Deep Network
Layout parsing outputs
Examples of manuscripts
Printed Sanskrit OCR
Given the large diversity in language, script and non-textual regional elements in historical Indic manuscripts, spatial layout parsing is crucial in enabling downstream applications such as OCR, word-spotting, style-and-content based retrieval and clustering. We take a significant step to address this gap and introduce Indiscapes, the first dataset with layout annotations for historical Indic manuscripts.

To succeed at layout parsing of manuscripts, we require a system which can accurately localize various types of regions (e.g. text lines, isolated character components, physical degradation, pictures, holes) and isolate individual instances of each region. To meet these requirements, we model our problem as one of semantic instance-level segmentation and introduce a deep-network based instance segmentation framework custom modified for fully automatic layout parsing.
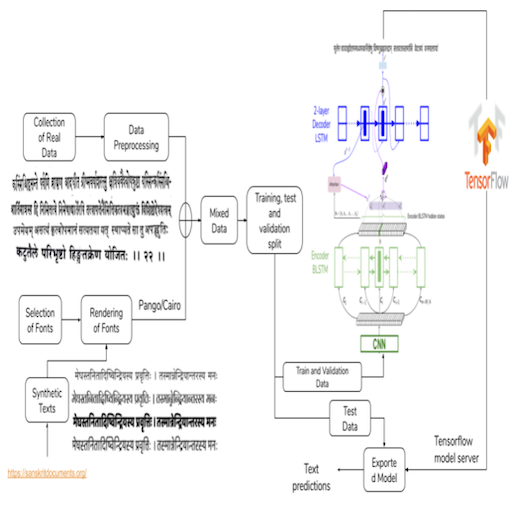
We introduce an OCR for Sanskrit texts printed in Devanagari and containing long, highly conjoined words. Our OCR achieves a word error rate of 15.97% and a character error rate of 3.71% on challenging Indic document texts.
We propose a web-based layout annotation and analytics system. Our system, called Historic Indic Document Layout Analyzer (HInDoLA), features an intuitive annotation GUI, a graphical analytics dashboard and interfaces with machine-learning based intelligent modules on the backend. HInDoLA has successfully helped us create the first ever large-scale dataset for layout parsing of Indic palm-leaf manuscripts, which in turn has enabled us to train deep networks for fully automatic instance-level layout parsing.
ETV Telangana (cable TV channel) covered our work on historical manuscript analysis in Yuva, a daily segment which covers young achievers. Watch the video below (in Telugu) and click on images for news articles.
 |
 |
Niharika Vadlamudi, Rahul Krishna, Ravi Kiran Sarvadevabhatla
International Conference on Document Analysis and Recognition (ICDAR 2023)
Khadiravana Belagavi,Pranav Tadimeti,Ravi Kiran Sarvadevabhatla
3rd ICDAR Workshop on Open Services and Tools for Document Analysis (ICDAR-OST)
SP Sharan, Aitha Sowmya, Amandeep Kumar, Abhishek Trivedi, Aaron Augustine, Ravi Kiran Sarvadevabhatla
International Conference on Document Analysis and Recognition (ICDAR 2021)
Abhishek Prusty, Sowmya Aitha, Abhishek Trivedi, Ravi Kiran Sarvadevabhatla
International Conference on Document Analysis and Recognition (ICDAR ’19)
Dr. Ravi Kiran Sarvadevabhatla
Center for Visual Information Technologies
IIIT Hyderabad, Hyderabad 500032, INDIA
E-mail: ravi.kiran@iiit.ac.in